Embracing the Future with Retrieval-Augmented Generation (RAG) in AI
Generative AI (GenAI) has come up to be a transformative force, making significant impacts across various sectors. GenAI, with its ability to generate text, images, audio, and other data types, is not just enhancing existing applications but is also paving the way for innovative possibilities.
The Power of Generative AI
Generative AI is a subset of AI technologies capable of creating content based on learned patterns and data. Unlike discriminative models that predict a label from input features, GenAI models generate entirely new data instances. Prime examples include GPT (Generative Pre-trained Transformer), which produces human-like text, and DALL-E, which creates images from textual descriptions. These models leverage extensive training data and complex neural network architectures to produce results sometimes indistinguishable from human-created content.

The utility of these models is vast. In healthcare, GenAI accelerates drug discovery by predicting molecular interactions more rapidly than traditional methods. In media, it powers tools that draft articles, personalize content, and generate scenes for virtual environments, enhancing engagement through tailored experiences. In the automotive sector, GenAI contributes to smarter AI that predicts maintenance issues and adapts to driving patterns for safety enhancements. Moreover, in cybersecurity and finance, GenAI is instrumental in developing new attack scenarios and analyzing market data for high-frequency trading, respectively.
The Need for RAG: Addressing GenAI’s Limitations
Despite its advancements, GenAI faces challenges, notably in tasks that demand up-to-date information or company-specific knowledge. This is where Retrieval-Augmented Generation (RAG) comes into play. RAG enhances the creative power of generative models by enabling real-time retrieval and utilization of the most relevant, context-specific information from extensive databases. This capability is vital as industries evolve, and previously trained models quickly become outdated.
A similar principle applies to creative workflows, where solutions like the Creative Suite API help businesses seamlessly generate and manage visual content, ensuring efficiency and relevance as industries evolve.
The Mechanics of RAG: Enhancing Contextual Relevance
Retrieval-Augmented Generation (RAG) addresses these limitations by seamlessly integrating external knowledge retrieval into the generative process, thus enhancing the capabilities of standard generative models.
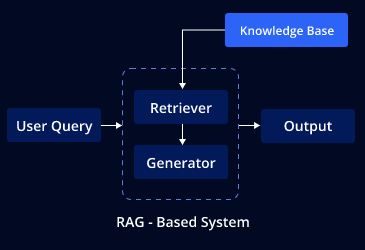
RAG is comprised of two primary components: a retriever and a generator. The retriever is tasked with searching through a vast knowledge base to find and retrieve the most relevant information. This could range from the latest industry news to specific technical details contained in proprietary documents. Once the relevant data is retrieved, it’s handed off to the generator.
The generator, often a sophisticated large language model (LLM), uses the retrieved information to craft responses that are informed, accurate, and contextually relevant. This dynamic interaction between the retriever and the generator allows RAG to produce outputs that reflect the latest developments and specific nuances of the subject matter, which are essential for applications requiring up-to-date information or deep domain expertise. 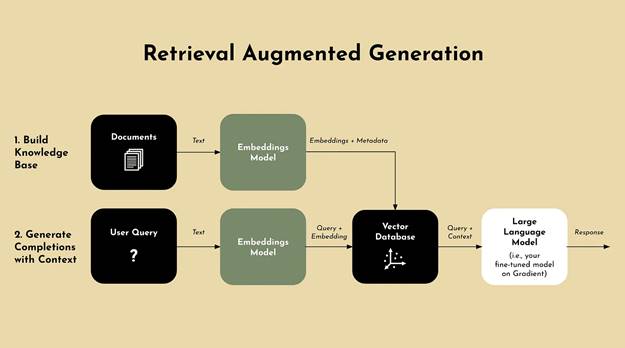
A common query arises here: why is searching necessary? Why can’t we simply furnish the entire knowledge base to the generator and allow it to extract the relevant information to generate responses?
The crux lies in the inherent token limit imposed by LLMs. Tokens, which represent units of text, are integral to how these models process information. However, LLMs have a finite capacity regarding the number of tokens they can effectively handle in a single input sequence. If we were to provide the entire knowledge base to the LLM without any preprocessing or filtering, it would likely exceed the token limit. Consequently, the model might struggle to process the vast amount of information comprehensively. Therefore, instead of inundating the LLM with the entirety of the knowledge base, a more strategic approach involves conducting targeted searches within the knowledge repository. This way, the model can focus its attention on the pertinent details necessary for generating accurate and contextually appropriate responses within the constraints of token-based processing.
Implementation of RAG: A Detailed Overview
- Data Preparation: The success of an RAG application hinges on a meticulously prepared knowledge base containing all relevant data, like company policies, product details, and technical documentation. This stage involves data deduplication, cleaning, formatting, and vectorization, where techniques like embeddings transform text into numerical vectors that capture semantic meanings for nuanced data retrieval.
- Fine-Tuning the Generator Model: Starting with a pre-trained model like GPT, the generator is fine-tuned with well-written, domain-specific prompts and examples, enabling it to generate text that is both accurate and contextually appropriate.
- Building the Retriever: The retriever employs methods such as vector similarity search and sparse retrieval to identify and fetch the most relevant data from the knowledge base, optimizing the process for efficiency and relevance.
- Integrating the Retriever and Generator: The final step involves integrating the retriever and generator to work seamlessly together. Once the retriever fetches the relevant data, it passes this information to the generator. The generator adjusts its responses based on the provided context, ensuring that the output is not only precise but also customized to specific needs of the query.
Step-by-Step Process of RAG: Unlocking the Mechanics
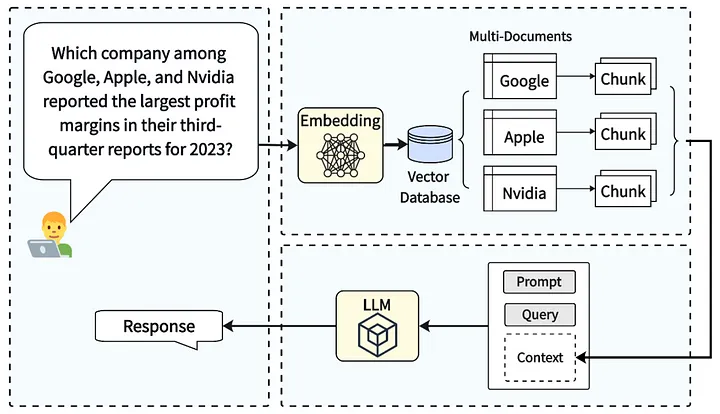
The process begins with the user entering a question. For instance, in the example depicted in the image below, the question posed is: “Which company among Google, Apple, and Nvidia reported the largest profit margins in their third-quarter reports for 2023?”
The user’s question is then transformed into a numerical representation, known as an embedding. This embedding allows the computer to analyze the query based on its semantic meaning, rather than merely the individual words.
The embedding is utilized to conduct a similarity search within a vector database, which acts as the retriever. This database is structured to facilitate efficient retrieval based on similarity.
The retriever identifies the most relevant documents related to the user’s query. These documents are typically presented as chunks of text and serve as context for subsequent processing.
The retrieved documents are provided as input to the Large Language Model (LLM). This additional context enhances the LLM’s ability to understand the query and formulate a suitable response.
Finally, leveraging the provided prompt and the retrieved documents, the LLM generates a response to the user’s query. This response is crafted based on the combined knowledge of the LLM and the retrieved context.
Practical Applications of RAG: Unlocking the Potential
The practical benefits of RAG are immense, particularly in customer support, where providing accurate and current information is crucial, or in sectors like healthcare and finance, where precision and up-to-date knowledge are imperative. By leveraging RAG, businesses can significantly enhance the functionality of their AI systems, making them more adaptive and valuable in practical scenarios. This innovative approach not only extends the lifecycle of generative models but also opens new avenues for customization and application-specific tuning.
Conclusion: The Strategic Importance of RAG in Tomorrow’s AI Landscape
As we delve deeper into the potential of Retrieval-Augmented Generation (RAG), it becomes increasingly clear that its impact on the field of artificial intelligence is not just incremental but transformational.
RAG offers a way to harness the full potential of generative AI while overcoming its inherent limitations. Looking ahead, the development and refinement of RAG technologies will likely focus on improving the efficiency of data retrieval and the accuracy of the generative outputs, ensuring that AI not only keeps pace with human needs but anticipates them. For IT professionals and businesses, investing in RAG technology means staying at the cutting edge of innovation, ready to leverage the next wave of AI capabilities.
By embracing RAG, we are not just optimizing our current systems but also paving the way for future advancements that will redefine what artificial intelligence can achieve.
Industries Benefits from Retrieval-Augmented Generation (RAG)
By integrating retrieval mechanisms with generative models, industries can benefit from Retrieval-Augmented Generation (RAG) in various ways, leading to several clear outcomes such as:
- Enhanced Decision-Making
- Improved Customer Service**
- Enhanced Research and Development (R&D)
- Streamlined Knowledge Management*
- Enhanced Marketing Strategies
- Competitive Advantage
- Cost Savings
- Enhanced Compliance and Risk Management
Practical Applications of RAG: Unlocking the Potential
As we continue to face complex challenges, RAG-based AI technologies offer a promising path forward. By implementing generative AI services using the Language Model (LLM) application architecture based on the RAG model and LangChain framework, industries can leverage RAG’s capabilities to achieve various benefits.
Enhanced Decision-Making
RAG leverages reinforcement learning to optimize decision-making processes while seamlessly integrating generative models to create custom solutions.
Advanced Question-Answering Systems
RAG models powers question-answering systems that retrieve and generate accurate responses, enhancing information access for individuals and organizations. For example, healthcare organizations can use RAG models to develop systems that answer medical queries by retrieving information from medical literature and generating exact responses.
Content Creation and Summarization
RAG models smoothen content creation by gathering relevant information from different sources, facilitating the development of high-quality articles, reports, and summaries. They also help generate coherent text based on specific prompts or topics. For instance, news agencies can leverage RAG models for the automatic news articles generation or summarizing lengthy reports, showcasing how versatile they are in aiding content creators and researchers.
Conversational Agents and Chatbots
RAG models enhance conversational agents, letting them fetch contextually accurate and relevant information via external sources. This ensures customer service chatbots, virtual assistants, and other conversational interfaces deliver correct and informative responses during interactions, making these AI systems more effective in assisting users.
Information Retrieval
RAG models improve information retrieval systems by enhancing the relevance and accuracy of search results. By integrating retrieval-based methods with generative abilities, RAG models enable search engines to recover documents or web pages based on user queries and generate informative snippets that effectively represent the content.
Educational Tools and Resources
RAG models, embedded in educational tools, revolutionize learning with personalized experiences. They adeptly retrieve and generate tailored explanations, questions, and study materials, elevating the educational journey by catering to individual needs.
Legal Research and Analysis
RAG models streamline legal research processes by retrieving relevant legal information and aiding legal professionals in drafting documents, analyzing cases, and formulating arguments with greater efficiency and accuracy.
Content Recommendation Systems
RAG models enhance content recommendation systems by delivering personalized suggestions as per user preferences and behaviors, thereby improving user engagement and satisfaction.
Future Potential and Business Integration
The RAG model is reshaping business operations by adding vital personalization, automation, and more informed decision-making to everyday processes, driving meaningful business and organizational value. As we look towards the future, the potential of RAG is promising a generation of more intelligent, responsive, and intuitive custom AI-powered applications.
By effectively implementing and leveraging RAG, industries can significantly enhance the quality of AI-generated content and achieve versatility across various sectors. RAG frameworks can be applied from global security to regulatory compliance, providing